

04: Machine Learning for Cyber Security¶
In this session we will cover:
- What is Machine Learning?
- What different machine learning approaches are there?
- How do we derive suitable features from our data, to then learn from?
What is Machine Learning?¶

A decision model that is not explicitly programmed, but instead is learnt through the training of example data.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it learn for themselves. We can essentially think of three components: an input (the data), a function, and an output.
The machine is trying to learn the function that can map inputs to some form of output, which is achieved by minimising some error measure (sometimes described as maximising a fitness function). One possible approach is to consider the difference between the expected output and the predicted output as the error measure - training is the process of iterative steps to reduce this measure.
Generative vs discriminative models¶
- In generative models, given some input data the model will aim to generate new samples (e.g., deepfakes).
- In discriminative models, given some input data the model will aim to discriminate between possible classes (e.g. classification).
Supervised Learning¶
This is where data is provided with training labels that inform the machine what the data is. For example, if we have a set of images that we wish to classify, we can state that the output is what the image depicts (for example, is it a cat or a dog?). The input to the system is the raw image data assessed based on colour pixel values. The output of the system is a label of either 'cat' or 'dog'. The function that converts the pixel input vector to a label output vector is what the machine attempts to learn. This is often described as classification.
Unsupervised Learning¶
This is where data is provided however no training labels are given. We want to learn some underlying properties about the data. Examples include clustering, where we aim to find hidden distributions within a larger set of data, association rules such as those used to identify shopping trends and similarities between consumer groups, and autoencoders that aim to learn suitable compression and decompression mechanisms for data representation and feature engineering.
Other forms of learning¶
- semi-supervised (where we may inform the system only on a subset of samples, as identified through some means which could be unsupervised)
- active learning (which involves a human-in-the-loop to label a small subset of data based on some underlying data attributes)
- reinforcement learning (which is learning based on trial-and-error, popular for learning to play video games or robotic navigation)
Methods of Machine Learning¶
Linear Regression¶
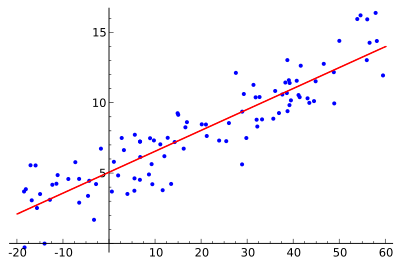
- Models linear relationship between a dependent variable (y, continuous output) and one or more explanatory (independent) variables (x, numercal input) - e.g., house prices, medical diagnosis, etc...
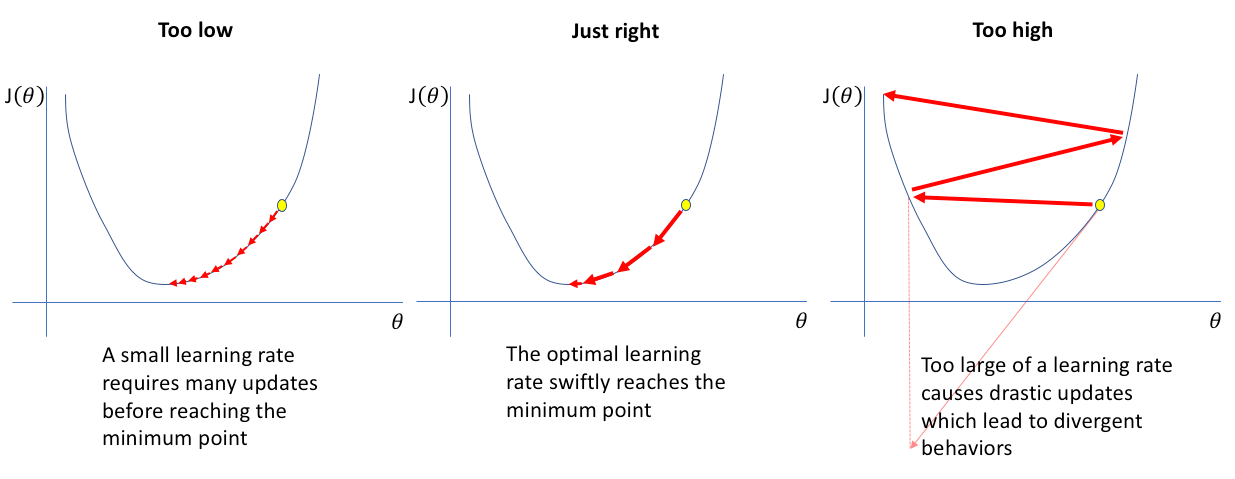
- $y = m_0 + m_1 X$ (where $m_1$ are learnt weights for each $X$).
- $m_0$ and $m_1$ learnt using Mean Square Error (MSE) and Gradient Descent.
#https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
X = np.array([ [1, 1], [1, 2], [2, 2], [2, 3] ])
#X = np.random.random([100,2])
y = np.dot(X, np.array([1, 2])) + 3
reg = LinearRegression().fit(X, y)
print ("X: ", X)
print ("y: ", y)
print ("Score: ", reg.score(X, y))
print ("Co-efficients: ", reg.coef_)
print ("Intecept: ",reg.intercept_)
print ("Prediction: ", reg.predict(np.array([[3, 5]])) )
#plt.scatter(X[:,0], X[:,1])
#plt.show()